
Google has mainly 3 parts
- Googlebot, a web
crawler that finds and fetches web pages.
- The indexer that
sorts every word on every page and stores the resulting index of words in
a huge database.
- The query
processor, which compares your search query to the index and recommends
the documents that it considers most relevant.
1. Googlebot
Googlebot consists of many
computers requesting and fetching pages much more quickly than you can with
your web browser. In fact, Googlebot can request thousands of different pages
simultaneously. To avoid overwhelming web servers, or crowding out requests
from human users, Googlebot deliberately makes requests of each individual web
server more slowly than it’s capable of doing.
Googlebot finds pages in two
ways: through an add URL form, www.google.com/addurl.html, and through
finding links by crawling the web.
2. Google’s Indexer
Googlebot gives the indexer the full text of the pages it finds.
These pages are stored in Google’s index database. This index is sorted
alphabetically by search term, with each index entry storing a list of
documents in which the term appears and the location within the text where it
occurs. This data structure allows rapid access to documents that contain user
query terms.
To improve search performance, Google ignores (doesn’t index)
common words called stop words (such
as the, is, on, or, of, how, why, as
well as certain single digits and single letters). Stop words are so common
that they do little to narrow a search, and therefore they can safely be
discarded. The indexer also ignores some punctuation and multiple spaces, as
well as converting all letters to lowercase, to improve Google’s performance.
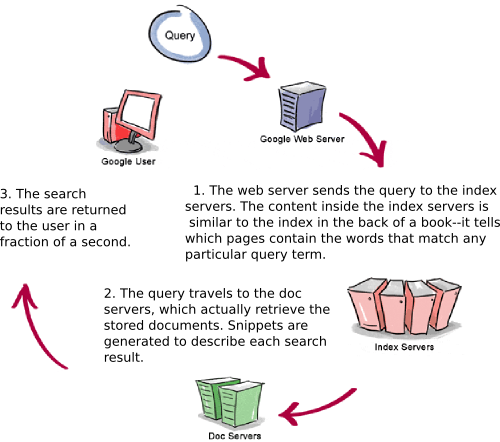
3. Google’s Query
Processor
The query processor has several parts, including the user
interface (search box), the “engine” that
evaluates queries and matches them to relevant documents, and the results
formatter.
PageRank is Google’s system for ranking web pages. A page with a higher
PageRank is deemed more important and is more likely to be listed above a page
with a lower PageRank.
Google considers over a hundred factors in computing a PageRank
and determining which documents are most relevant to a query, including the
popularity of the page, the position and size of the search terms within the
page, and the proximity of the search terms to one another on the page. A patent
application discusses
other factors that Google considers when ranking a page. Visit SEOmoz.org’s
report for an
interpretation of the concepts and the practical applications contained in
Google’s patent application.
Google also applies machine-learning techniques to improve its
performance automatically by learning relationships and associations within the
stored data. For example, the spelling-correcting system uses such techniques to figure out likely alternative spellings.
Google closely guards the formulas it uses to calculate relevance; they’re
tweaked to improve quality and performance, and to outwit the latest devious
techniques used by spammers.
Indexing the full text of the web allows Google to go beyond
simply matching single search terms. Google gives more priority to pages that
have search terms near each other and in the same order as the query. Google
can also match multi-word phrases and sentences. Since Google indexes HTML code
in addition to the text on the page, users can restrict searches on the basis
of where query words appear, e.g., in the title, in the URL, in the body, and
in links to the page, options offered by Google’s Advanced Search Form and Using Search Operators (Advanced Operators).
A Web page's PageRank depends on a few
factors:
·
The frequency and location of keywords within the Web page: If the keyword only appears once within the
body of a page, it will receive a low score for that keyword.
·
How long the Web page has existed: People create new Web pages every day, and
not all of them stick around for long. Google places more value on pages with
an established history.
·
The number of other Web pages that link to the page in question: Google looks at how many Web pages link to a
particular site to determine its relevance.
No comments:
Post a Comment